GPU 性能测试
本篇主要讲述关于 GPU 性能测试的方法及在北京超算平台的测试

Beijing: ☀️ 🌡️+33°C 🌬️↓4km/h
写在前面
深度学习中,我们在训练一个大模型或完成较大的任务之前,都需要对硬件环境进行评测,特别是 GPU 的性能进行测试,尽管官方已经给出了不同显卡在对应任务上的表现,但是不同的计算机配置(除 GPU 之外的硬件)也会影响其训练性能,因此我们需要进行实测,其主要有两个目的:
- 🤸 评估整个任务完成所需要的时间以及成本估计
- 💯 在可选择方案中,选择最具性价比的方案
- 🆎 计算资源有限的情况下,尽可能消耗极致性能
由于就不同的配置环境,本篇的目的主要有:
- 如何评测一个任务在实际硬件中的性能
- 如何理解实际性能和理论性能的差别
- 理解计算的瓶颈,通过调节参数提高训练的性能
网络结构逐层分析
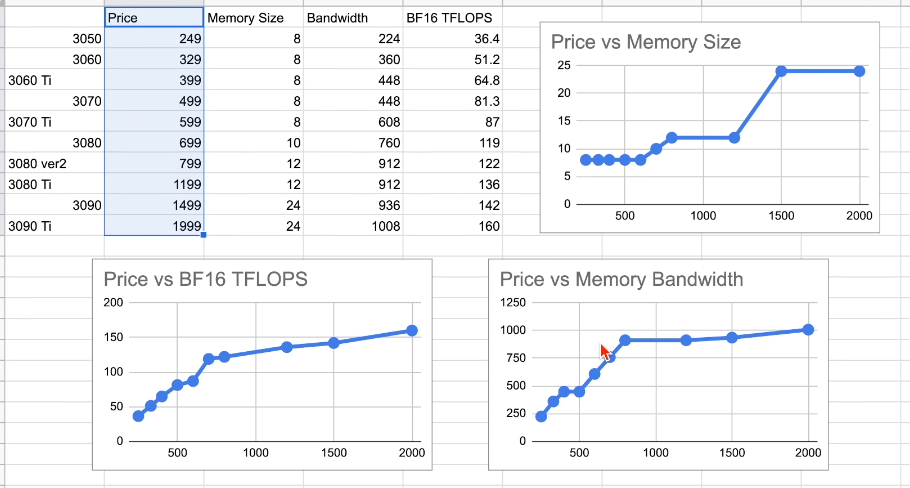
| A100 | A6000 | V100 | 3090 Ti | |
|---|---|---|---|---|
| Theory TF32(FP32) / FP16 | 156 / 312 | 75 / 150 | 16 / 125 | 80 / 160 |
| Memory (GB) / Bandwidth (GB/s) | 80 / 2039 | 48 / 768 | 32 / 900 | 24 / 1008 |
| Approximate Price $ | 16,000 | 4,000 | 3,500 | 1,500 |
| Matrix Multiplication FP32 / FP16 | 116 / 230 | 60 / 95 | 14 / 95 | 42 / 81 |
| Vector Multiplication | 0.202 | 0.082 | 0.098 | 0.107 |
| Bert Layer Forward / Forward+Backward | 110 / 136 | 60 / 70 | 53 / 64 | 56 / 62 |
| GPT-2 Layer Forward / Forward+Backward | 45 / 53 | 35 / 38 | 32 / 36 | 37 / 39 |
| T5 Encoder Forward / Forward+Backward | 44 / 56 | 34 / 41 | 31 / 38 | 36 / 41 |
| T5 Decoder Forward / Forward+Backward | 38 / 47 | 28 / 34 | 26 / 32 | 30 / 36 |
训练
总结
关于 batch size 选择
- 🧴 提升 batch size 途径
- 使用较大显存的 GPU
- 使用较低精度 16 位浮点数类型
- 合并运算降低中间变量存储的开销
- 梯度累加
- 梯度 check points
- 🥉 存在问题
- 较大的 bs 会导致收敛变慢,需要更多次的迭代
- Fine-tuning 时需要选择较小的 bs,因为一般而言,测试数据集的多样性并非很丰富,Pre-tranining 过程中可以选择较大的 bs
- 当 GPU 增加到成百上千的时候,能分配的 bs 相对较小
关于多卡训练
- 尽可能使用数据并行
- 🅰 满足条件
- 模型能够放到单卡的内存
- bs 满足训练需求
- 💢 优点
- 通讯模式相对简单
- 通讯和运行有一定的并行度
- 性能表现相对较好
- 🅰 满足条件
- 不能使用数据并行的情况下,使用 zero 划分模型中间状态,或张量并行
- 做张量并行最好选择较大的带宽,NV-Link 是相对较好的选择
北京超算 GPU 资源测试
以下是对北京超算 GPU 性能测试过程的相关说明:
- 本次测试的目的:① 对比采用’fp16’,‘batch size’,‘num_GPUs’以及不同 GPU 资源配置对模型预训练时间及推理时间的影响;② 估算训练模型所耗费的时间成本和经济成本;③ 根据已有的算力资源配置,选择合适的训练参数,保证 GPU 资源得到充分利用。
- 本次采用的算力资源皆来自于北京超算,测试脚本中,采用模型为 transform 类的 BERT 系,共有参数 184551780,预训练任务为 MLM,主要使用 Huggingface 的 Transformers 的 Trainer 类进行训练,wandb 记录运行相关日志;
- 这里记录时间仅为模型预训练和推理的时间,不包括 tokenizer 的训练以及文件的 IO 相关;
- 原始语料共有数据:训练集(1994187)、验证集:(104838),本次使用 datasets 的 select 方法对数据进行随机采样,最终模型所使用的数据为:训练集(2048)、验证集:(1024),同时为每次训练语料的一致性,使用 transfomers 下的 set_seed 方法设置随机种子;
- 本次模型训练过程中,在每个 epoch 结束后在验证集上进行一次推理测试,即每轮参数在验证集上的推理 2 次,epoch 总数为 2,梯度累积步数(gradient_accumulation_steps)为 4;
- V100_4gpu_8表示采用 4 块 V100 GPU,每个 GPU 上的 train 和 eval 的 batch size 都为 8,total_train_bs 表示 🧉num_GPUs*gradient_accumulation_steps*train_bs_per_device;
- V100 配置
- CPU:Gold 61 系列(72vCPU) v5@2.5GHz
- 内存:320GB
- GPU:8 * NVIDIA®Tesla ® V100 SXM2
- 显存:8 * 32GB(897 GB/s)
- NVLink: 双向通信 300 GB/s
- 操作系统:CentOS7.8
- 单卡按需(元/卡/时)💰5.3
- A100 配置
- CPU:Intel 6248R(48C)@3.0GHz
- 内存:384GB
- GPU:8 * NVIDIA®Tesla®A100 PCIe
- 显存:8 * 40GB(1555 GB/s)
- 节点互联:100G RoCE(RDMA 协议)
- 操作系统:CentOS
- 单卡按需(元/卡/时)💰9.3
- 节点包月(元/节点/月) 👍50,112
测试结果如图所示:
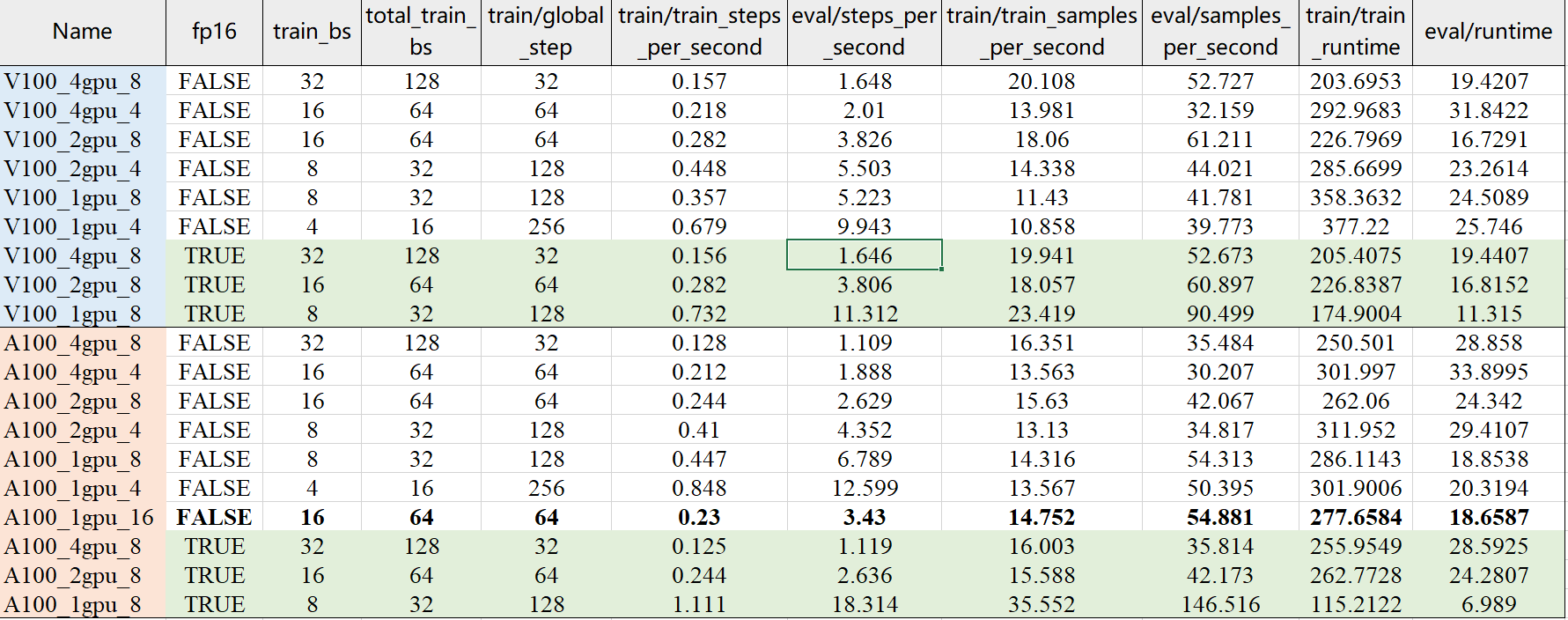
| Name | fp16 | train_bs | total_train_bs | train/global_step | train/train_steps_per_second | eval/steps_per_second | train/train_samples_per_second | eval/samples_per_second | train/train_runtime | eval/runtime |
|---|---|---|---|---|---|---|---|---|---|---|
| V100_4gpu_8 | FALSE | 32 | 128 | 32 | 0.157 | 1.648 | 20.108 | 52.727 | 203.6953 | 19.4207 |
| V100_4gpu_4 | FALSE | 16 | 64 | 64 | 0.218 | 2.01 | 13.981 | 32.159 | 292.9683 | 31.8422 |
| V100_2gpu_8 | FALSE | 16 | 64 | 64 | 0.282 | 3.826 | 18.06 | 61.211 | 226.7969 | 16.7291 |
| V100_2gpu_4 | FALSE | 8 | 32 | 128 | 0.448 | 5.503 | 14.338 | 44.021 | 285.6699 | 23.2614 |
| V100_1gpu_8 | FALSE | 8 | 32 | 128 | 0.357 | 5.223 | 11.43 | 41.781 | 358.3632 | 24.5089 |
| V100_1gpu_4 | FALSE | 4 | 16 | 256 | 0.679 | 9.943 | 10.858 | 39.773 | 377.22 | 25.746 |
| V100_4gpu_8 | TRUE | 32 | 128 | 32 | 0.156 | 1.646 | 19.941 | 52.673 | 205.4075 | 19.4407 |
| V100_2gpu_8 | TRUE | 16 | 64 | 64 | 0.282 | 3.806 | 18.057 | 60.897 | 226.8387 | 16.8152 |
| V100_1gpu_8 | TRUE | 8 | 32 | 128 | 0.732 | 11.312 | 23.419 | 90.499 | 174.9004 | 11.315 |
| A100_4gpu_8 | FALSE | 32 | 128 | 32 | 0.128 | 1.109 | 16.351 | 35.484 | 250.501 | 28.858 |
| A100_4gpu_4 | FALSE | 16 | 64 | 64 | 0.212 | 1.888 | 13.563 | 30.207 | 301.997 | 33.8995 |
| A100_2gpu_8 | FALSE | 16 | 64 | 64 | 0.244 | 2.629 | 15.63 | 42.067 | 262.06 | 24.342 |
| A100_2gpu_4 | FALSE | 8 | 32 | 128 | 0.41 | 4.352 | 13.13 | 34.817 | 311.952 | 29.4107 |
| A100_1gpu_8 | FALSE | 8 | 32 | 128 | 0.447 | 6.789 | 14.316 | 54.313 | 286.1143 | 18.8538 |
| A100_1gpu_4 | FALSE | 4 | 16 | 256 | 0.848 | 12.599 | 13.567 | 50.395 | 301.9006 | 20.3194 |
| A100_1gpu_16 | FALSE | 16 | 64 | 64 | 0.23 | 3.43 | 14.752 | 54.881 | 277.6584 | 18.6587 |
| A100_4gpu_8 | TRUE | 32 | 128 | 32 | 0.125 | 1.119 | 16.003 | 35.814 | 255.9549 | 28.5925 |
| A100_2gpu_8 | TRUE | 16 | 64 | 64 | 0.244 | 2.636 | 15.588 | 42.173 | 262.7728 | 24.2807 |
| A100_1gpu_8 | TRUE | 8 | 32 | 128 | 1.111 | 18.314 | 35.552 | 146.516 | 115.2122 | 6.989 |
📖 参考文献
💬 评论